3 Management Functional Areas
Last update
PvD
3.5 PM
Performance Management
Overview
- Standard
- Purposes
- Quality of Service
- Issues
Standard
[M.3400]: Performance Management (PM) provides functions to evaluate and report the behavior of telecommunication equipment and the effectiveness of the network or network element.
Its role is to gather statistical data for the purpose of monitoring and correcting the behavior and effectiveness of the network, NE or equipment and to aid in planning and analysis.
As such, it is carrying out the performance measurement phase of Recommendation M.20.
A TMN collects Quality of Service (QoS) data from NEs and supports the improvements in QoS. The TMN may request QoS data reports to be sent from the NE, or such a report may be sent automatically on a scheduled or threshold basis.
At any time, the TMN may modify the current schedule and/or thresholds.
Reports from the NE on QoS data may consist of raw data which is processed in the TMN, or the NE may be capable of carrying out analysis of this data before the report is sent.
Quality of Service includes monitoring and recording of parameters relating to:
- connection establishment (e.g. call set up delays, successful and failed call requests);
- connection retention;
- connection quality;
- billing integrity;
- keeping and examining of logs of system state histories;
- cooperation with fault (or maintenance) management to establish possible failure of a resource and with configuration management to change routing and load control parameters/limits for links etc.;
- initiation of test calls to monitor QoS parameters.
In general, Performance Management must provide tools to perform the following tasks:
- Performance monitoring
- Performance monitoring involves the continuous collection of data concerning the performance of the NE. Acute fault conditions will be detected by alarm surveillance methods. Very low rate or intermittent error conditions in multiple equipment units may interact resulting in poor service quality and may not be detected by alarm surveillances. Performance monitoring is designed to measure the overall quality, using monitored parameters in order to detect such degradation. It may also be designed to detect characteristic patterns before signal service quality has dropped below an acceptable level.
The basic function of performance monitoring is to track system, network or service activities in order to gather the appropriate data for determining performance.
- Generic functions (Request PM data, PM data report, Start/stop PM data, Initialize PM data).
- Traffic status monitoring. These functions provide current status of the network and its major elements. Current status may be reported to the operator directly by the NE, or may be provided to the operator by an Operations System (OS), which collects the status information from one or more NEs.
- Traffic performance monitoring functions. These functions relate to the assessment of the current performance of the network and the traffic being offered and carried. Performance monitoring may be performed directly with the exchange or be an operations system which provides these functions with one or more NEs.
- Performance (management) control
- Generic functions (Scheduling of performance monitoring, etc.).
- Traffic control functions These functions relate to application, modification and removal of manual and automatic network management traffic controls. Manual controls may be manipulated by the operator directly with the exchange under control, or through an operations systems which interfaces with one or more exchanges. Automatic controls are applied automatically by the exchanges according to the operating parameters of the control. Operators may intervene either directly or through an operations system to establish, modify, remove or override an automatic control.
- Traffic administrative functions. These are the functions and activities in the exchange and operations system which relate to the support of the network management function.
- Performance analysis
- Performance data may require additional processing and analysis in order to evaluate the performance level of the entity.
- Generic functions (Report PM analysis, Request PM analysis).
Performance Management usually concerns huge amounts of data. Handling such amounts of data is a problem in itself. The main point however is, that data is not information; it lacks purpose.
Specifying the purpose may allow reduction/aggregation of data in an earlier stage and/or at a lower level.
Purposes for Performance information
The main purposes for Performance Management are:
- Capacity Management
- Predict network usage (trend), predict performance (QoS problems) and adapt capacity (i.e. extend or reduce the network, modify allocations, priorities, etc).
Overcapacity leads to poor profitability, whereas insufficient capacity causes severe quality loss; the right balance is important. This is independent from any specific user, but related to overall traffic on equipment, i.e. capacity and usage, and consequently to QoS.
It does require the collection and aggregation of quite a large amount of data from dispersed sources to a central destination. The results are preferably in an 'SML view' on the network: e.g. a traffic matrix.
Capacity Management includes real-time Performance Monitoring and Performance Control for what is commonly called Traffic Management.
- Maintenance Surveillance, i.e. problem detection and prediction
- Detect equipment malfunction through performance problems and predict problems by monitoring quality trends (e.g. noise levels, error rates, laser deterioration, etc).
Instead of central collection of performance data to check proper operation, one may compare values (typically 'rates', i.e. events per time) against their thresholds at the suitable places across the network; exceeding such a threshold should signal a performance alarm: the so-called Threshold Crossing Alarm (TCA; potentially through Leaky Bucket techniques).
However, probably not all such monitoring can be implemented as threshold crossings; the need for some collection remains but no aggregation is required (i.e. basically a distributed application).
- User service quality
- This is specific for each service by the user, potentially even for each service instance. The relevant QoS parameters achieved for that service should be recorded similar to the detailed billing record (potentially integrated with the CDR), in particular when they not meet the standard and fines are probable {there is considerable overlap with AM}.
Specific issues are:
- Customer specific reporting (what parameters, what presentation);
- Service Level Agreement (SLA) management: striving for the achievement of SLAs (i.e. monitor QoS and intervene in allocations/priorities); and
- CNM: what information does the customer needs/wants.
Typically, one requires very little information when everything is all right (i.e. a summary is sufficient); when there are problems however, nearly 'all' available data is wanted: one needs the capability to 'drill down' i.e. request more detailed information in specific areas.
Quality of Service
The performance of a system can best be judged along the (ITU-T) recommendation for Quality of Service (QoS) for Availability per type of request (service/action):
- Dependability
- against outages; commonly called 'availability';
- Accuracy
- against errors; typically 'error rates';
- Speed
- delay and throughput, potentially synchronisation: wander and jitter (delay variation);
for the (connection) phases
- Engagement;
- Transfer; and
- Disengagement
of a telecom service. {See [Q.822] ?}.
Above parameters are basically independent but sometimes related by definition. E.g. for transmission, when exceeding a certain interval with bit errors ('accuracy'), the connection is assumed to be out-of-service ('dependability'). That makes sense, but complicates processing and reporting of such values.
Typical QoS parameters are:
- Service provisioning time (for customer care purposes);
- Integrity of administrative data;
- Availability of service;
- Call error rate (for connection oriented switched services, due to network);
- Call set-up delay (for connection oriented switched services);
- Bit error rate (noise levels), errored seconds;
- Delay (for interactive services);
- Delay variation or jitter (phasing errors) for synchronous services;
- Synchronicity (frequency error or wander) for synchronous services;
- Throughput (for variable bandwidth services: i.e. bits/bytes/packets/frames/cells per interval);
- Integrity of billing data.
The important thing is that the relevant QoS parameters are different for each service, or even for each (service) application. E.g. for voice and video, the bit error rate can be quite high before it is even noticed, whereas data transport is rather vulnerable for bit errors.
Some services are extremely sensitive to delay variation (e.g. jitter for voice), whereas for others (data transport) this is irrelevant.
It implies that a service is qualified by its QoS parameters. When the service is used for various purposes/applications, multiple service grades should be offered. It is not only the level of a particular QoS parameter which varies with the service (e.g. availability 99.9% versus 99%); new QoS parameters may appear and others may disappear:
it's a different set of QoS parameters, and it leads to distinct service classes (typically a standard class, a premium class and customised classes).
In formalised form it becomes a contract: a Service Level Agreement (SLA) or a Service Level Guarantee (SLG).
This view has a serious impact on Performance Management, and as a consequence, for the network and its management. When the distinct services are expressed in their QoS parameters, they should be assured by the network and measured by Performance Management.
It implies that network capacity planning should use those QoS parameters to size the network, and network management should be capable to measure and report these. It requires a performance model of (each of the components in) the network to predict service performance {and SLA guarding}. It is likely to lead to grouping/allocating network resources for specific service classes.
Note that the above-mentioned QoS parameters are only some parameters in basic form; one may provide them in a more elaborate form. For example, the parameter dependability (or availability) can be presented as a single value (e.g. 99.73%), but also in a more elaborate form like 'total outage', 'number of outages', 'average outage', 'longest outage'.
Presentation is important for perception and appreciation.
Issues
Performance management requires gathering of statistics, maintenance and examination of logs, and adaptation of equipment and system behavior. It concerns a huge amount of data; intelligent reduction is paramount. This assumes purpose and performance models.
The challenges are:
- Modelling
- Determine the relevant QoS parameters and represent them in a performance model.
This is specific to the service application (i.e. there will be a model per service class); the relevant parameters will evolve over time.
- Model the network components.
Express the network component's characteristics in QoS (model-)terms.
- Reporting
- Find suitable presentations for performance information.
This is also the quest for 'comprehensive' versus 'sufficient' information; a 'drill-down' capability might solve some cases.
- Acquisition
- Collect data.
Collecting enormous amounts of data about the network (through the same or special network {DSN}).
- Aggregate data to information
- Dealing with large amounts of data, handling missing data, late- or temporally skewed data, incomparable data.
- Reduce data to significant information.
Interpreting data taking into account such problems as 'direct routes', 'overflow routes', etc.
Other means such as the insertion of sample/test traffic and the use of Call Detailed Record's Call Clear Reason may aid here.
From above, it will be clear that there is no simple 'final solution'.
Apart from the current non-ideal starting point, requirements will evolve and implementation will have to adapt.
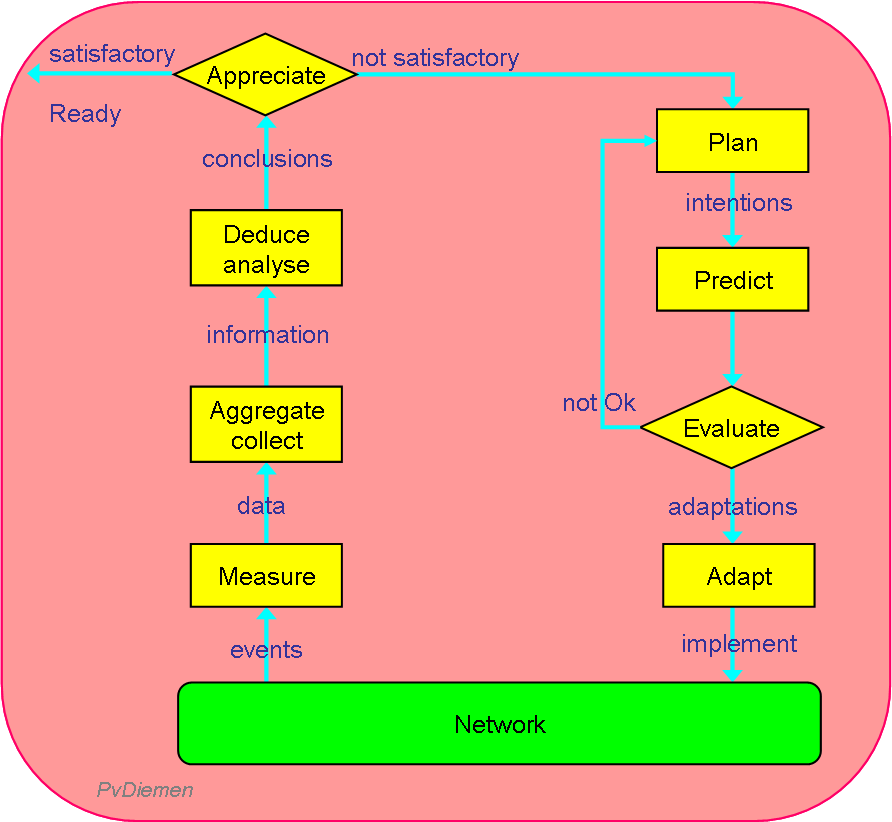
The basic cycle is: measure (& collect & aggregate) → analyse/deduce → plan → adapt.
Note however that this cycle is applicable at two levels of abstraction:
- for Performance Management (adapt network, i.e. improve utilisation: capacity/quality management); and
- for determining relevant performance indicators (adapt metrics: i.e. improve Performance Management).
Performance management gives a good insight in the operation of the system, and supplies clues for performance enhancements. The handling of overload conditions for both the managed network and the management system is a Performance Management issue (it may cause a 'Performance Alarm', which is forwarded to Fault Management); it is very treacherous subject as it is difficult to exercise (traffic control) commands in an overloaded system (but essential for survival).
Further references:
- SLA creation
- Some simple rules for the creation of SLAs.
- Capacity Management process cycles
- More information on network planning and traffic control.
=O=